


| Home |
| Questionnaires |

|
| DataBases |
 |
|
 |
| Contact |
| Copyright DDL-CNRS |
The DiaDM Project
A web-based platform for Diachronic Data and Models
Welcome to the DiaDM project
The DiaDM project is a Web-based collaborative platform that aims to compile, organize and explore hypotheses about the putative
processes by which the diversity of the world's languages came to be and the structures of the protolanguages from which today's
languages are supposedly derived. The targeted 'data' are therefore reconstruction hypotheses of proto-structures, proto-lexicons
and sound change.
Goals
The ultimate goal of the DiaDM project is to create tools and resources to manage the evolving universe of data and methods
about the evolution of languages in such a way that researchers from inside as well as outside the field of linguistics can
easily comprehend their larger context ("what processes justify this reconstruction?"), compare and contrast hypotheses
("where do these two language relationship hypotheses agree and disagree?"), identify patterns and tendencies and synthesize
concepts and data into ever more comprehensive and useful models and methods to reconstruct the past of today's languages. As
such, the DiaDM Project aims to facilitate the access, development and testing of hypotheses about the evolution of languages
by providing a unified framework in which a range of exploratory methods complement a body of comparable and directly
interpretable reconstruction hypotheses from diverse language areas and families.
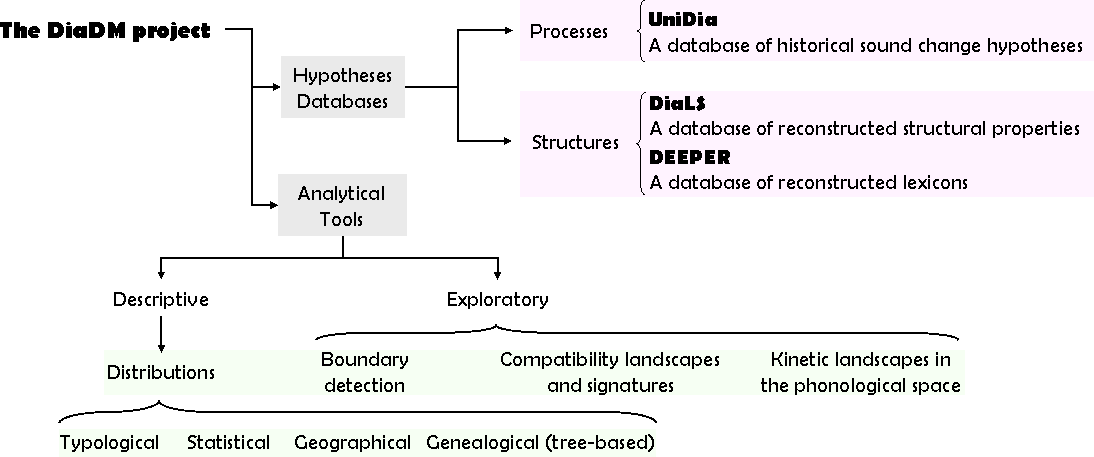
Featured databases
The DiaDM project hosts three databases, each surveying the type of hypotheses emitted during the reconstruction process.
Processes are covered by UniDia, a database for historical
sound change and structures are covered by DiaLS, a database of
reconstructed structural properties and DEEPER, a database of reconstructed
proto-lexicons. These three databases are associated with a set of analytical tools that allow both descriptive and exploratory
enquiries. The architecture of the DiaDM project is as follows:
How to use
The DiaDM project is designed to allow the community of linguistic experts to author, curate and connect a diversity
of proto-language reconstruction hypotheses, and the scientific community at large to access this body of data in a
comprehensive and unified format to develop and experiment original analytical approaches.
To ensure the quality of the data, we have developed a fully public Web resource associated with secure personal workspaces.
Any expert willing to contribute with personal or published data can therefore manage his/her data entry and checking
procedures, and we have devoted a great deal of effort reduce the time necessary to do so.
If you are interested in participating to the DiaDM project, please
contact us
and we will provide you with a login and a password giving you access to the database as a contributor. Comments, suggestions
or reports of inconsistencies are also very much welcomed.
Browsing requirements
If you don't have them already, you will need to install
Charis SIL, a Unicode-based font and
Flash Player.

Warning
The DiaDM project is still under construction.
We apologize for the inconvenience.
If you find it is taking too long, contact us for updates.